Where, Oh Where are the Statisticians?
April 26, 2019

Conor Artman, PhD Candidate
April 26, 2019
Conor Artman, PhD Candidate
In the timeless words of Alyssa Edwards, “I’m back, back, back, back, back again.”
It’s been a while, so let me remind you about my research—I am interested in modeling illicit network behaviors. In my last blog post, I described some of the challenges faced in such problems and argued that taking a “bottom-up” approach based on agent-based models (ABMs) lends itself well to identifying a solution. Agent-based models are not unique to studying illicit networks; many different fields use ABMs. You might even be very familiar with ABMs and not realize it! For example, if you are an operations researcher studying traffic management, an economist designing macroeconomic simulations for “what-if” market scenarios, a financial analyst designing bots to trade automatically for you, or even a marketing analyst studying how news propagates through social networks on Twitter, you may be readily familiar with ABMs. If you are an ecologist, you might know them as Individual-Based Models (IBMs). In short—ABMs are used to model a variety of complex phenomena!
If you were reading that closely, you might have noticed that I never mentioned statisticians! In fact, there is NO statistical theory for developing, analyzing, and assessing ABMs! This is particularly puzzling as in all of the fields mentioned it is extremely common for statisticians to help design simulations or assist in operationalizing mental models to generate or assess empirical evidence—think of chemometrics, econometrics, psychometrics, geostatistics, demography, astrostatistics, biostatistics, or (more recently) reinforcement learning as examples. But for some reason, statisticians have been largely out to lunch when it comes to ABMs.
The good news is that their absence does not (completely) wreak havoc: to validate an ABM as being “good” in some qualitative sense, all you need is a pair of human eyes attached to a human brain!
The bad news is that all you need is a pair of human eyes attached to a human brain!
Currently, to validate massive ABMs (imagine simulating the entire U.S. economy, for instance), modelers typically bring in an expert in their field of study to eyeball the simulation as it runs in real time and to basically give a thumbs-up or thumbs-down. If the ABM is reasonable enough in some heuristic sense to satisfy a minimum standard of face-validity (i.e., does the model’s behavior even seem plausible, as compared to our understanding of how the world works currently?), it gets a thumbs-up. Otherwise, thumbs-down. On one hand, this is an essential feature of any model. Would you trust a traffic simulation model that concludes optimal traffic behavior is for all vehicles to never drive? Or a weather simulation claiming tomorrow’s forecast includes car-sized hail and 400-degree Celsius heat? Absolutely not! On the other hand, this is a disturbingly low bar, given how ubiquitous ABMs are for informing high-consequence decisions. (As an easy example, the Federal Reserve still uses ABMs to study trajectories of outcomes under different policy changes.) If this approach seems like a reasonable place to stop in assessing model validity, let me illustrate why this is a bad idea from the perspective of cognitive psychology.
Even though we have a whole part of our brain that has evolved over many millions of years to give us shockingly powerful and efficient visual pattern classification, it is surprisingly easy to find and exploit “bugs” in our cognition. A perfect and easy example is the Müller-Lyer illusion. In the picture below, all three line segments are exactly the same length, but if you consider the topmost picture, it looks as though each of the lines could be different lengths. Looking at the bottom-most picture, we can see that this is not the case.
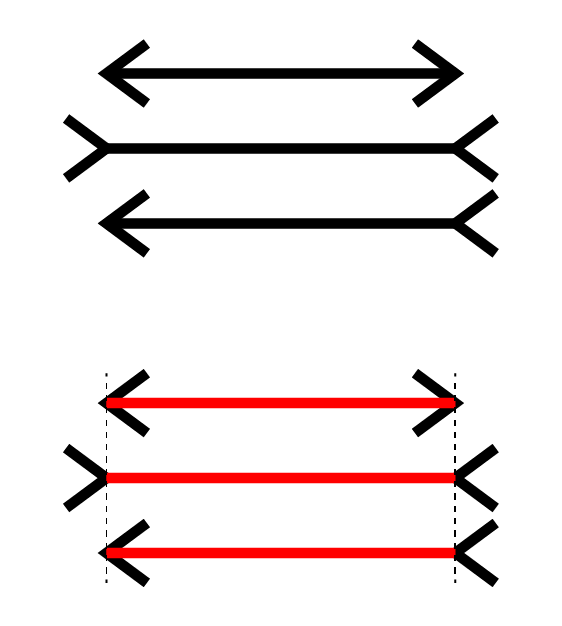
This point is easy to discount, so let me reinforce it: even though we have an extremely efficient and powerful set of machinery dedicated to visual processing in our brains, we can easily trick a simple assessment of length with what amounts to stick figures. Now imagine you have to watch a richly complex set of agents interacting over time, with agents possibly following some entangled and nonlinear fashion of behavior, for an hour or so. How confident would you really be in claiming that the ABM passes the standard of ‘face-validity’, given that we know how easy it is to trick our visual processing?
I think it would be conservative to say that this process is error-prone. And while I don’t have the space to discuss this further, these biases in our cognition are exacerbated by other well-known biases such as confirmation bias, the availability heuristic, base-rate neglect, and motivated reasoning.
Keeping this idea in mind, face-validity offers a necessary but insufficient condition for validating complex ABMs. Even if face-validity with our eyes were sufficient, this addresses only one part of a multiplex problem—let’s say I have 3 ABMs that produce very similar data. How do I decide which one is “best” among them? How do I know when an ABM I have coded up is “good enough” to represent the complex real-world phenomenon it seeks to study? When should I replicate an episode of an ABM simulation, and when do I know I have enough data to stop altogether? And let’s say I run a massive ABM simulating something like a city-wide evacuation plan under threat of a dirty bomb, or an Ebola outbreak in Liberia—what is a principled, standardized way that we could use to analyze both ABMs? Depending on the analyst, one scientific question may be operationalized into a longitudinal study on the data produced by an ABM, or maybe the same question would be operationalized as reinforcement learning problem. In that case, ABMs are even divergent in comparing evidence from the same simulation among analysts. All of these remain open questions, but they are at the very least open questions that historically lie in a statisticians’ wheelhouse—thus how bizarre it is that we haven’t seen very much activity from statisticians!
Luckily, there have been some exceptions. An exciting direction in statistical research is taking place by exploring Approximate Bayesian Computing (ABC) and emulators in the context of ABMs. Considering ABMs from the perspective of emulators, one can start to see a direction for a principled theory of ABMs that looks akin to a linear model—this would be great, as linear models have a huge literature of tools at their disposal that handily give us direct ways to answer the kinds of questions posed earlier, but to find out we clearly need more statisticians jumping into the fray. We are currently exploring this avenue, and I’ll update you on our findings in my next post!
Conor is a PhD Candidate whose research interests include reinforcement learning, dynamic treatment regimes, statistical learning, and predictive modeling. His current research focuses on pose estimation for predicting online sex trafficking. We asked a fellow Laber Labs colleague to ask Conor a probing question.
If you were to form a cult, what common interest would it be based around and how would you recruit followers?
One idea is a cult that works behind the scenes to run a society called Bertrand’s Tea Salon! Or maybe something more superficially prestigious sounding like, the Bertrand Society of Empiricists or some nonsense. The selection criteria? The depth of specious reasoning! Our order would pore over all scientific literature to find those who are truly worthy. Once selected, our group would cultivate membership under the guise of a rigorous peer-review process, where recruitment takes the form of flattery via email. The name is in homage to Bertrand Russell’s teapot analogy. Directly from Wikipedia:
As a fine example of such a claim that would merit entry into my cult, consider the statement, “[Insert phenomenon here] would exist even if we didn’t have statistics!” For example, “The endowment effect would exist even if we didn’t have statistics to observe it!”, or “Priming and the availability heuristic would exist even if we didn’t have a way to measure it!”
Now you may ask, “Why, Conor, why is this such a crock of shit?” And I’ll tell you why: The assertion that a phenomenon would still exist, after originally not knowing it existed and then discovering that it exists after a rigorous scientific process, is a marvelous exercise in hindsight-biased counterfactual reasoning.
One way to think of this would be the now-beaten-to-death question, “If a tree falls in the woods without anyone around to see it, does it still make a sound?” After having observed trees, the sounds they make when they fall, and generally coming to understand their behavior, it seems like a completely reasonable assertion that trees, in general, should probably make noise when they fall even when unobserved. But, this is very different from saying that after never having observed trees, never having observed their sounds, and having never observed their general behavior when they fall, that we can assert that trees behave the same way. Why? Because if we’ve never observed trees before, we have no experience or data to draw from, and we can’t construct an inductive argument.
Put another way, imagine all of human history, knowledge, and data is erased tomorrow, and we forget any and all discoveries the human race has made. From our perspective in this erasure-reality, we don’t know any of the results we previously knew, and we don’t have any evidence for our conjectures and intuition. Even if for some reason we had some great intuition about some phenomenon existing, we could not assert that this phenomenon exists without some form of evidence. Is it possible that some scientific process or phenomenon still persists regardless of if we’ve gone to the trouble of precisely observing it? Of course. Is that the same thing as then being able to assert that it still does exist, when we don’t have any data available? Absolutely not! And why is that? Russell’s teapot! If I told you that I and a group of special other individuals “knew” there is a massive sentient teapot orbiting the moon at such an angle that no one has ever observed it except us, then clearly the burden of proof is on us to demonstrate this.
So, if I tried to assert the truth of some result from the erasure-reality, but now without any proof, then from our new (mind-wiped) perspective this would be equivalent to stating the research question, simply claiming that it’s true, and calling it a day. In any case, this would be an A+ way to receive an induction ceremony into Bertrand’s Tea Salon.
In summary, my recruitment method is an appeal to human vanity and insecurity under the guise of peer review, and one-by-one my legion of specious scientists would grow day-by-day, fueled by humankind’s congenital well-spring of self-deception and self-interest!
This is Conor’s second post! To learn more about his research, check out his first article here!